Figure 1 — Where two worlds converge: simulation science meets the generative AI era

The Spark
A few years ago, I watched a cellular automaton demo — Rule 30, one of Stephen Wolfram’s favorites — and something clicked. Here was a system governed by a rule so simple you could write it on a napkin, yet the patterns it produced were wild, unpredictable, and eerily reminiscent of real-world chaos. Wolfram called this computational irreducibility: for certain complex systems, there is no shortcut. You cannot predict the outcome without actually running the computation, step by step. The only way to know what happens is to let it play out.
That idea lodged itself in my brain and never left.
I come from a background in systems design and optimization — data center resource management, embedded AI, heterogeneous SoC architecture simulation. My daily work involves building models of complicated machines and finding ways to make them run better. But increasingly, I’ve found myself drawn to a different kind of system. Not silicon. Not software stacks. People. Communities. Societies.
Agent-based modeling (ABM) offers a framework for doing exactly this: you define individual agents with their own rules, drop them into an environment, and watch what emerges. It’s the computational equivalent of asking, “What happens when a million small decisions collide?” And the answers, much like Wolfram’s cellular automata, are often surprising.
Figure 2 — From simple rules to complex societies
But here’s what makes this moment different from any that came before. ABM has been around for decades. What’s new is a collision of forces — generative AI, massive GPU compute, and differentiable simulation frameworks — that is fundamentally reshaping what these models can do and what they mean. And at the same time, a quieter but more profound shift is underway: AI agents are no longer just tools for simulating society. They are becoming participants in it.
Consider a thought experiment. A Tuesday afternoon in 2028. A product team at a mid-sized tech company is negotiating next quarter’s budget — but nobody is in the same room. Each team lead has spent twenty minutes that morning briefing their personal AI agent: priorities, red lines, acceptable trade-offs. The agents spend three hours negotiating with each other — proposing, counter-proposing, escalating sticking points back to their human principals. By 4 PM, a draft allocation lands in everyone’s inbox.
Figure 3 — When humans brief agents: from the meeting room to agent-to-agent negotiation
Science fiction? The pieces are already on the table. LLM-based agents can negotiate and coordinate in constrained strategic settings. Researchers have built multi-agent societies of thousands with emergent norms and social dynamics. We are at the beginning of understanding what happens when the boundary between “simulation subject” and “real-world actor” starts to dissolve.
That dual realization — that we’re simultaneously building better tools for studying society and reshaping the society being studied — is what pulled me into this space. After digging into the literature and stress-testing my intuitions against what I know about systems engineering, I want to share some observations. Not as an expert in computational social science, but as a systems thinker who sees structural parallels and open questions that deserve more attention.
Here’s the map as I see it: three forces converging on ABM right now — better interaction, bigger scale, smarter agents — plus a wild card (When AI Agents Join Human Society) that could reshape the whole game. But the story that ties them together isn’t the one you’d expect.
The Obvious Story — and Why It’s Incomplete
When you first survey ABM in the generative AI era, three directions jump out:
Make it more visual and interactive. Social simulations ultimately serve human understanding. If the results can’t be explored and questioned by people, the simulation is a black box with extra steps.
Make it bigger and richer. Many phenomena — tipping points, emergent norms, cascade failures — only materialize at sufficient scale. Wolfram’s computational irreducibility gives theoretical weight to this: if you must run the system to see what happens, fidelity depends critically on scale.
Make the agents smarter. With LLMs capable of reasoning and communicating in natural language, the temptation is obvious: replace rule-based agents with AI-powered ones that can think, talk, and adapt.
These directions are real and well-supported. But after deeper investigation, I’ve come to believe this “bigger, smarter, prettier” narrative misses the most important part of the story.
The real frontier isn’t about making simulations bigger or agents cleverer. It’s about making the entire research process trustworthy.
Figure 4 — The real axis: trustworthiness across visual, scale, and intelligence
Classical ABM often treated the model as the main deliverable: build it, run it, plot the output, write a paper. But the field has been quietly shifting toward a layered research stack:
Source ingestion → Concept extraction → Model specification → Simulation → Calibration & sensitivity → Validation → Interactive interpretation → Reproducibility & audit
Each layer can fail independently. A simulation might produce beautiful emergent behavior and still be scientifically useless — because the input data was silently biased, the calibration overfitted while ignoring subgroups, or the “emergent” pattern was an artifact of a poorly specified rule.
This reframing matters because many criticisms of ABM — “it’s just a toy,” “you can make it produce anything” — are really about weak upstream mapping or absent downstream validation, not the simulation paradigm itself. Once you see ABM as a stack, the question shifts from “How big can we build?” to “How accountable can we make every layer?”
For someone with a systems engineering background, this feels like coming home. It’s the same thinking that distinguishes a prototype from a production system: the core computation may be identical, but the observability, testing, provenance, and failure-handling infrastructure is what makes it trustworthy.
With that framing, let me walk through the three forces — and the wild card — with a sharper lens.
Force #1: Making the Invisible Visible
Let’s start with something that sounds obvious but is surprisingly hard: making simulation results understandable to humans.
ABM simulations can produce staggering amounts of data — millions of agents, billions of interactions, sprawling parameter spaces. But the consumers of these insights are people: policymakers, urban planners, researchers. If the output is a wall of numbers only a specialist can parse, we’ve won the battle of computation and lost the war of understanding.
This is not just a visualization problem. It’s an interaction design problem.
The ABM community already has capable tools — Mesa’s browser-based dashboards, GAMA Platform’s spatial visualization, Repast’s multi-view inspection. But most current tools are good at showing what the simulation produced. Far fewer help you understand why, which mechanisms drove the outcome, or how confident you should be. The most valuable insights come from iteration — a researcher poking at the model mid-run, asking “What if I changed this?” or “Why did that cluster behave that way?”
Figure 5 — From black-box outputs to a live, provenance-aware analysis copilot
Generative AI opens a genuine research opportunity here — not prettier dashboards, but what I’d call mechanism-oriented, provenance-aware interactive analysis. Imagine a simulation copilot that lets you query a running simulation in natural language: “Show me the moment polarization began to accelerate.” “What factors correlate with agents who defected from the norm?” “Summarize this run and flag the anomalies.” Each answer comes with a provenance trail — where the data came from, what assumptions were made, how sensitive the conclusion is.
For anyone who’s worked on observability in distributed computing — tracing requests through microservices, correlating logs across components — this has a familiar shape. The ABM analysis workbench is, in a sense, an observability platform for simulated societies.
And there’s a deeper reason this matters: as we incorporate AI-driven agents into simulations, explainability becomes critical. If an LLM-powered agent makes a surprising decision, can we explain why? The human-in-the-loop isn’t just a usability feature — it’s a safeguard for scientific rigor.
Force #2: Scale Changes Everything — But Not How You Think
A provocative claim: most agent-based models today are too small to tell us what we really want to know.
Simulating 1,000 agents can reveal interesting dynamics. But many phenomena — pandemic spread, market crashes, political polarization — are inherently large-scale, emerging from vast numbers of heterogeneous actors, and behaving very differently at population scale than in a small sandbox.
The infrastructure is finally catching up. FLAME GPU 2 brings GPU-accelerated ABM with flexible agent communication. AgentTorch (MIT Media Lab, built on PyTorch) simulates millions of agents on commodity GPUs, is fully differentiable, and has already modeled COVID-19 dynamics across New York City’s 8.4 million residents. Repast4Py extends Repast into Python with MPI-based cluster distribution.
Figure 6 — Sandbox versus population scale: where emergent behavior actually shows up
AgentTorch deserves special attention from anyone with an optimization background. Differentiable simulation changes the game: gradient-based calibration instead of brute-force sweeps, one-shot sensitivity analysis via automatic differentiation, end-to-end optimization coupling simulation with learned modules. This isn’t a performance trick — it changes the epistemic workflow.
And there’s a beautiful irony: the AI hardware boom has produced an explosion of GPU capacity worldwide. Frameworks like AgentTorch turn tensor-processing units into social simulation engines. The same chips built to power chatbots can also power digital societies.
But scale without validation is just expensive noise.
The bottleneck is no longer “Can we run a million agents?” It’s “Can we calibrate a million-agent model and prove it’s trustworthy — not just for the aggregate, but for specific subgroups?” Calibrating a large-scale stochastic ABM against heterogeneous data is structurally similar to hard systems-optimization problems: high-dimensional parameter spaces, non-convex landscapes, identifiability issues. There’s significant room for improvement here.
Where LLMs Help (and Don’t) in Data Preparation
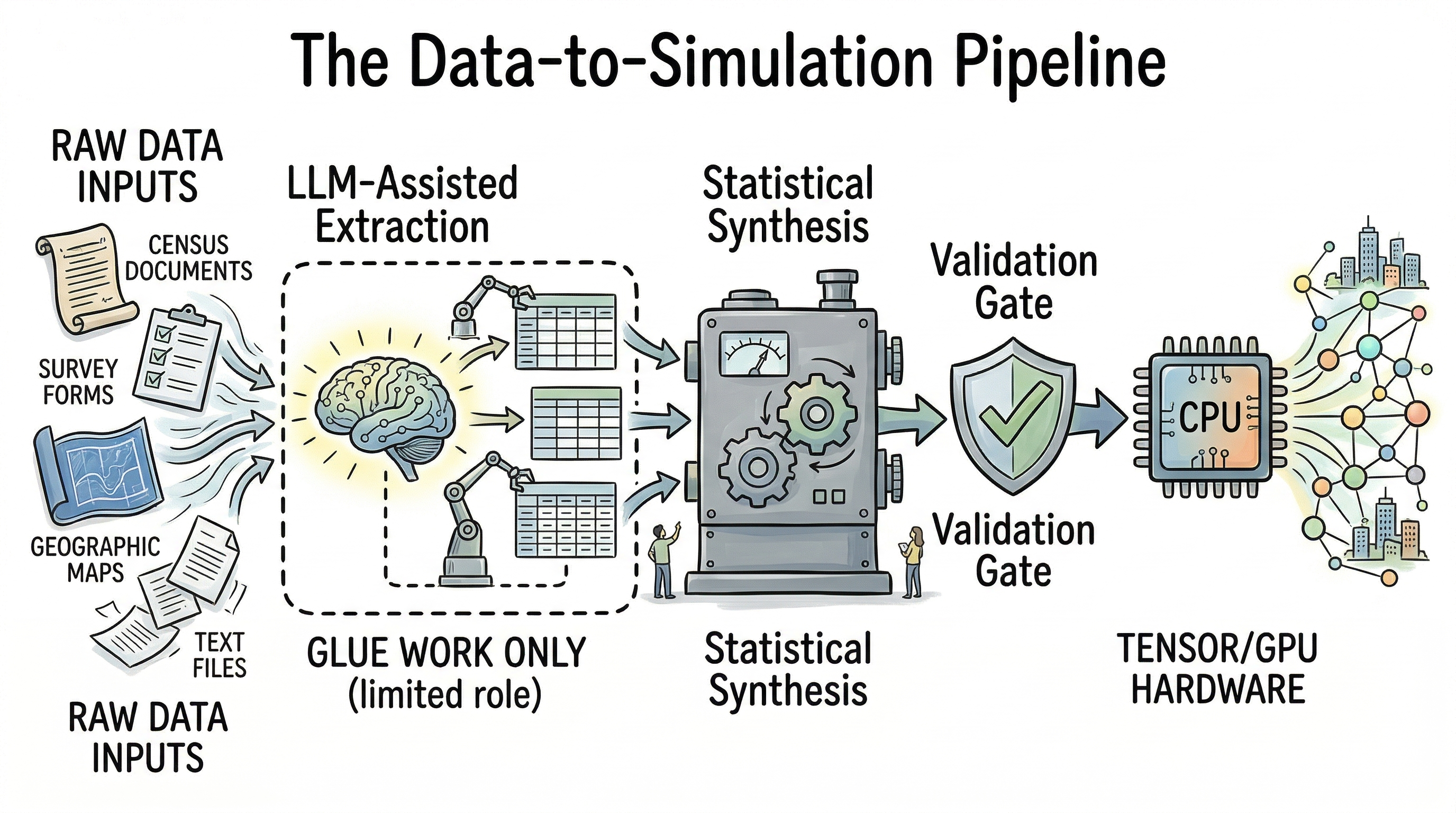
Building realistic large-scale simulations also requires rich input: demographic distributions, network structures, behavioral patterns. Traditionally a massive bottleneck.
LLMs provide genuine value in the “glue work”: extracting constraints from messy documents, mapping schemas across data sources, generating documentation, auditing synthetic population pipelines. What they should not yet be trusted to do is generate population characteristics directly — the risk of importing training-data stereotypes into a simulation’s foundation is too high. Census-derived synthetic populations via statistical methods remain the defensible core. LLMs are best positioned as pipeline assistants, not replacements.
Figure 7 — Data to simulation: LLMs as pipeline glue, statistics as the defensible core
Force #3: Smarter Agents — Scaffolded, Not Autonomous
The first two forces improve ABM’s infrastructure. This one changes the nature of the agents themselves — and generates the most excitement and the most risk.
Traditional ABM agents follow simple rules: if-then logic, probability distributions, utility functions. Useful, but brittle. Real humans are contextual, adaptive, and maddeningly inconsistent.
Enter generative agents. In 2023, Joon Sung Park and colleagues created a town of 25 LLM-powered agents that planned their days, formed relationships, organized a Valentine’s Day party, and spread information through social networks — exhibiting emergent behaviors never explicitly programmed. Since then, Project Sid scaled to 1,000+ agents developing professions and democratic laws in Minecraft; AgentSociety simulated 10,000+ agents reproducing polarization and policy-response dynamics.
Impressive engineering. But the central challenge isn’t making agents more eloquent — it’s making the system trustworthy.
Figure 8 — Three generations of agents—and the validation wall before “eloquent” counts as evidence

The Integration Spectrum
Integrating LLMs into ABM is a spectrum of architectural patterns with different cost-fidelity trade-offs:
LLM as policy generator: the simulation core stays fast; the LLM periodically produces goals or decision templates. Minimizes API calls, preserves reproducibility.
Archetype-based querying: query representative types and apply responses to clusters of similar agents. AgentTorch’s “LLM archetypes” formalizes this — but how much diversity do you sacrifice for feasibility?
Differentiable hybrid architectures: tensorized backbone with LLM modules for decision logic and communication, optimizable end-to-end.
This framing — agency as a resource to allocate and optimize — resonates strongly with my background in heterogeneous computing resource management. The parallels are structural: managing computational resources with different cost-quality trade-offs, under constraints linking local decisions to global behavior.
The Validation Wall
The uncomfortable truth: LLM-driven agents can produce behavior that looks realistic without being scientifically valid.
A simulation might generate fluent dialogue, plausible demographic variation, and convincing narratives — and still fail because its causal mechanisms are wrong, subgroup behavior is distorted by training-data bias, or apparent emergence is actually memorized pre-training patterns. This is the deepest reason validation has become the field’s central problem.
Hallucination: a fabricated agent memory can propagate through the network and distort emergent outcomes. Grounding strategies become methodological necessities.
Representation gap: LLMs capture majority viewpoints; computational social science needs specific subpopulations. An LLM might generate a convincing response for a “65-year-old farmer in rural Indonesia,” but how faithful is it? Domain-specific fine-tuning or specialized foundation models may be needed.
Black box: when an LLM agent acts, the reasoning is locked inside billions of parameters. Could we bridge this by connecting internal model states to social science theories — mapping activation patterns to bounded rationality or conformity pressure? It’s ambitious and carries epistemic risk, but even a more grounded step — behavioral interpretability under controlled conditions — would be valuable.
A long shot. But the kind of cross-disciplinary challenge that keeps me excited.
The Wild Card: When AI Agents Join Human Society
The three forces above describe how we build better simulations of human society. The wild card asks a different question: what happens when agents leave the simulation and operate in the real world alongside us?
This isn’t hypothetical. AI agents already complete purchases on behalf of users, negotiate in constrained economic settings, and manage routine transactions. The infrastructure for agent-to-agent commerce is being actively built. Industry analysts project trillions of dollars in AI-mediated consumer commerce by decade’s end.
Now extrapolate from shopping to everything else.
Figure 9 — Hybrid marketplace: humans, AI delegates, and agent-to-agent flows

Remember the budget negotiation thought experiment from the opening? That’s one instance of a broader pattern. Corporate coordination, economic transactions — buying a house, bidding in an auction — even routine commerce could increasingly be conducted by AI agents on behalf of human principals. AI agents armed with comprehensive market data could level the playing field, giving every participant expert-level support.
And here’s a question I keep returning to: if your customer’s first point of contact is their AI agent, who does the advertisement need to convince? Does “brand loyalty” mean anything when an algorithm makes the purchasing decisions? The internet and smartphones radically changed commerce because they redirected human attention to digital screens. If attention shifts to AI intermediaries, the entire logic of persuasion and information design may need reinvention.
This isn’t just speculation. Research on reinforcement-learning pricing agents shows they can learn to sustain supra-competitive prices without explicit communication — a phenomenon resembling algorithmic collusion that has already raised regulatory concerns.
A New Unit of Analysis
For computational social science, the unit of analysis shifts. We need to model not just humans, but:
- Human principals and their intent
- AI delegates and their capabilities, biases, and failure modes
- Platforms and institutions mediating the interactions
- Oversight structures maintaining human control
This is a systems problem at the deepest level — not how smart one agent is, but what emergent institutional behavior arises when entire organizations and markets are AI-mediated.
And a civilizational question: if we outsource negotiation, argument, and compromise to machines, what happens to our social skills, our empathy, our ability to navigate conflict?
Figure 10 — New unit of analysis: principals, delegates, platforms, oversight
Connecting the Dots: A Layered Research Stack
Stepping back through a systems engineering lens, these four themes aren’t independent directions — they’re layers of a single research stack.
Figure 11 — The unified research stack: from scalable simulation backbone to hybrid society frontier
The foundation: a scalable, validation-first ABM backbone. This is the technical spine. Build a simulation system that is hardware-accelerated and designed from the ground up with subgroup-sensitive validation as a first-class requirement. This is where systems engineering and optimization experience maps most directly — the problems of calibrating high-dimensional stochastic systems, managing heterogeneous computational resources, and building robust testing infrastructure are deeply familiar.
The interaction layer: provenance-preserving, LLM-assisted exploration. Use LLMs to reduce friction across the research workflow — extracting rules from literature, querying simulation results in natural language, generating documentation — but with full traceability. Every LLM-generated element should carry a provenance tag. This layer is immediately actionable and provides the foundation for validating everything above it.
The validation layer: formal benchmarks for LLM-enhanced ABM. Turn vague concerns about “realism” and “bias” into concrete, testable criteria. Can the model reproduce known subgroup differences? Does it remain stable across random seeds, prompt variations, and model versions? Do intervention experiments produce theoretically consistent responses? This is the layer that transforms ABM from a storytelling tool into a scientific instrument.
The application frontier: controlled testbeds for AI-mediated institutional interaction. Start with well-defined settings — negotiation, budget allocation, auction mechanisms — and study what happens when agents mediate human goals. This is where fundamental research meets practical relevance.
The long-term frontier: understanding the hybrid society. Once AI agents become routine intermediaries in commerce, governance, and communication, how do we model the co-evolution of human and artificial actors? Who designs the information that AI agents consume? How do persuasion, framing, and manipulation work when the first audience is an algorithm?
These aren’t five separate projects. They’re layers of one stack, and the strength lies in their integration.
Looking Ahead
I don’t claim to have the answers. I’m a systems engineer with deep curiosity about complex social systems, not a social scientist with decades of domain expertise. But cross-pollination between fields is exactly what this moment requires. The challenges of scaling social simulation, making it interactive, and integrating AI are fundamentally systems problems.
What excites me most is the convergence. For the first time, we have language models that approximate human behavior, hardware for population-scale simulation, frameworks bridging the two, and — if we build it right — validation infrastructure to keep it honest.
Figure 12 — Convergence: LLMs, hardware, and social simulation into a trustworthy stack
If there’s one thesis I’d want readers to take away: the most impactful contributions won’t come from building the biggest simulation or the smartest agent. They’ll come from building the most trustworthy research stack — transparent in its assumptions, rigorous in its validation, honest about its limitations, and designed to keep humans meaningfully in the loop.
And if society increasingly involves AI agents as mediators and participants in human institutions, building that stack isn’t just academic. It’s a prerequisite for understanding the world we’re building.
That’s a question worth spending a career on.
I’m a systems engineer by training, with a background in modeling, simulation, and optimization for computing architectures. I’m drawn to the intersection of agent-based modeling, computational social science, and AI — not because I have answers, but because I find the questions irresistible. If these threads resonate, or if you think I’m wrong about something, I’d love to hear from you. The best research comes from conversations between people who see the world differently.