Figure 1 — Overview: everyday contrasts and the hidden architectures beneath
A Tale of Two Supermarkets
Figure 2 — Two supermarket worlds: regulation, density, and delivery as system outcomes

A few years into living in Europe, I found myself standing in front of a closed supermarket on a Sunday afternoon, grocery bag in hand, feeling mildly annoyed. Back in China, I could have walked into any convenience store on any street corner at nearly any hour. Here, the nearest shop was a fifteen-minute drive away — and it was closed.
That small inconvenience stuck with me longer than it should have. Not because it was a hardship — it wasn’t — but because it was a thread I kept pulling. The more I pulled, the more I realized it was connected to something much larger: a web of interdependent social mechanisms that shape how entire societies function, how organizations operate, and how individuals experience daily life.
I have spent most of my career working on complex IT systems — optimizing resource allocation in cloud data centers, designing simulation models for heterogeneous processor architectures, and studying cache behavior in CPUs. These are systems where small design choices ripple outward, where trade-offs are everywhere, and where the “best” solution is almost never obvious. As I moved between Asia and Europe, I started noticing that human societies behave in strikingly similar ways. The same architectural tensions I wrestled with in computing — centralization vs. distribution, efficiency vs. resilience, responsiveness vs. autonomy — seemed to play out in the streets, hospitals, offices, and governments around me.
This blog post is an attempt to lay out those observations honestly. I am not here to declare which system is better. I am here to share what I have seen, the questions these observations raise, and why I believe computational modeling — particularly agent-based modeling — might be one of the most powerful lenses through which to study these dynamics.
Part I: The Fabric of Everyday Life
Convenience, Autonomy, and the Price of a Service
Figure 3 — Household self-reliance versus app-mediated service access
Living in Europe, you learn to be self-reliant fairly quickly. You mow your own lawn. You fix a leaky faucet yourself, or you pay a serious premium for a plumber. You file your own taxes — a process that can consume an entire weekend of gathering documents, navigating government portals, and double-checking figures. You plan your grocery shopping for the week, because the store may not be open when you need it.
In China, the rhythm is different. A quick tap on your phone brings a repairman to your door at a fraction of the European cost. Tax filings and bank procedures, while not paperwork-free, are handled with remarkable speed by dedicated service staff. Food delivery — fast, cheap, and available at almost any hour — is not a luxury but a daily routine for millions of working professionals. Convenience stores dot every neighborhood, open seven days a week, often late into the night.
At first glance, one might simply label one society “inconvenient” and the other “convenient.” But that framing misses the deeper story. These are not random differences — they are emergent properties of interconnected social mechanisms, each reinforcing the other.
The Feedback Loop Nobody Designed
Here is what I keep turning over in my mind.
In Europe, individuals reserve significant personal time for managing their own affairs. This means less of their time is available for providing services to others. Naturally, when someone does offer their time as a service, it commands a higher price. High service costs, in turn, reinforce the habit of self-reliance. And because people need that personal time, working hours and shop opening times are kept within boundaries — further reducing service availability. The cycle continues: lower convenience, higher autonomy, and a social norm that accepts slower timelines.
In China, the dynamic runs in the opposite direction. Affordable third-party services encourage people to outsource daily tasks. But here is the part that is easy to overlook: every service consumed is a service someone else must provide. The delivery rider working through his lunch break is enabling your lunch break. The bank clerk processing your paperwork at 7 PM is freeing your evening. As more people rely on services, demand grows, working hours extend, personal time shrinks — and the need for yet more services increases. The service is cheap, so everyone uses it. Everyone uses it, so everyone is busy providing it.
Which came first — the cheap service or the dependency on it? Is the low price a cause or a consequence? And once this feedback loop is in motion, would raising prices even change anything?
I genuinely do not know the answers. But I find the questions fascinating, because they describe a classic complex adaptive system — one where macro-level patterns emerge from micro-level interactions, and where causality is circular rather than linear.
Figure 4 — Reinforcing loops behind autonomy and convenience
Tolerance for Delay: A Hidden Variable
There is another dimension to this: the collective expectation around how fast things should happen.
In Europe, people seem to carry an implicit assumption that things take time. A government permit might take weeks. A medical appointment might be months away. An online order might arrive in three to five business days. And that is fine — because the social contract is built around this pace. You plan ahead. You wait. Life adjusts.
In China, the baseline expectation is speed. Same-day delivery. Government approvals processed in hours. Instant responses on messaging apps. When something takes longer than expected, the friction is real — not just logistically, but emotionally. The tolerance for delay is lower because the system has trained everyone to expect immediacy.
This is not a matter of patience or impatience as personal traits. It is about what the system conditions its participants to expect. And that conditioned expectation, in turn, shapes the system itself.
So What Does Each Pattern Produce?
Neither pattern is inherently superior. Each generates distinct outcomes that may be advantageous in different contexts.
The European pattern, with its emphasis on individual autonomy and slower rhythms, seems to create conditions where people have more cognitive and temporal space. Less time pressure, more room for reflection. One might speculate — and this is only speculation — that this could partially explain why certain forms of artistic creativity and fundamental scientific inquiry have historically flourished in Western contexts. These are activities that often require unstructured time and a tolerance for slow, uncertain progress.
The Chinese pattern, with its emphasis on collective efficiency and rapid service delivery, generates extraordinary throughput. This is a system optimized for speed — for scaling up production, for industrializing new technologies, for executing massive infrastructure projects in compressed timeframes. When the goal is rapid development and large-scale deployment, this system excels.
But these are hypotheses, not conclusions. The actual mechanisms are far more complex, shaped by history, culture, policy, demographics, and countless other variables. Understanding them properly requires more than anecdotes — it requires rigorous, systematic investigation.
Part II: The Organization as a Microcosm
Figure 5 — Trust-based coordination versus process-heavy hierarchy
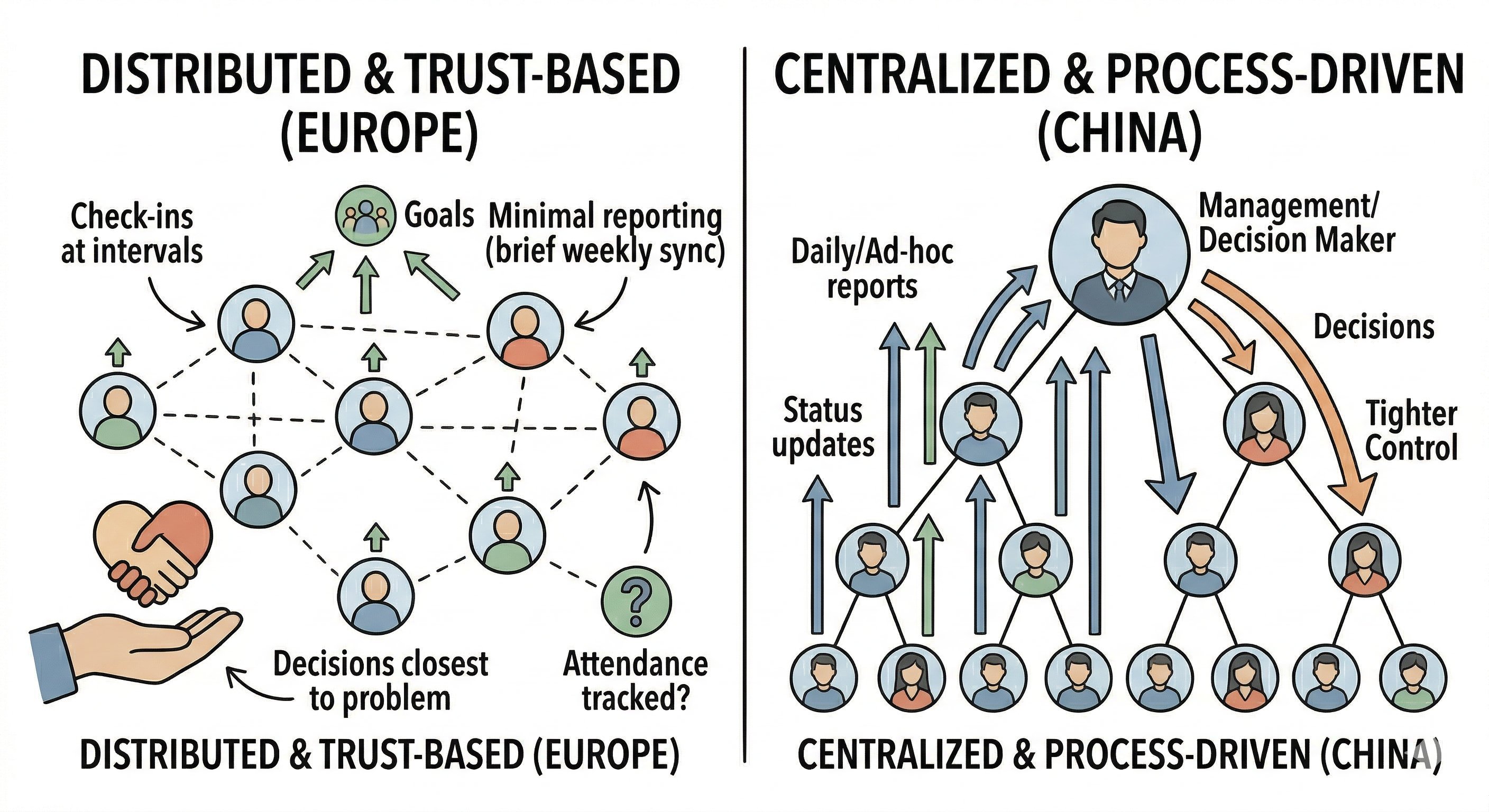
The patterns I observed at the societal level also showed up at a smaller scale — inside the teams and organizations I worked in.
Trust-Based vs. Process-Based Management
In European teams I have been part of, the management style leaned toward what I would call distributed and trust-based. Goals and milestones were set collaboratively, and once agreed upon, people were largely left to execute independently. Check-ins happened at defined intervals, not constantly. Reporting was minimal — a brief weekly sync, perhaps a monthly review. Decisions that did not require strategic alignment were made by the individual closest to the problem. Even attendance tracking was relaxed: as long as you delivered quality work on time, nobody questioned whether you were at your desk at 9 AM.
In Chinese teams I have worked with, the style was noticeably different — more centralized and process-driven. Daily reports, weekly reports, sometimes even ad-hoc status updates requested at short notice. Decisions, even relatively minor ones, often escalated to higher management layers. Objectives shifted more frequently, which in turn necessitated frequent realignment meetings. Attendance was tracked carefully. The overall feel was one of tighter control — management wanting visibility into the process, not just the outcome.
Why the Difference — and Does It Matter?
Again, I resist the urge to judge. Instead, I find myself asking: what produces these different patterns, and what does each pattern produce in return?
The trust-based model works well when requirements are stable and individuals are empowered to make local decisions. It minimizes communication overhead — something any distributed systems engineer knows is critical. Each person can enter a state of deep focus, iterate on their work without frequent interruption, and produce outputs that benefit from sustained attention. For tasks requiring creativity, innovation, or meticulous craftsmanship, this model seems well-suited.
But when requirements change rapidly, this model can be slow to respond. A distributed system with infrequent synchronization may drift out of alignment. Adaptation requires propagating new information to all nodes, and that takes time.
The process-driven model, by contrast, is highly responsive to change. Frequent reporting means management has near-real-time visibility. Centralized decision-making means pivots can happen quickly. This is valuable in fast-moving markets, in large-scale operations where coordination is paramount, and in environments where the cost of misalignment is high.
The trade-off? The communication overhead itself becomes a significant load. When a substantial portion of everyone’s workday is consumed by status updates, alignment meetings, and report preparation, less time remains for the actual work. Individual focus is fragmented. And paradoxically, the heavier the process burden, the more management may feel the need to monitor closely — because they sense that productivity is not where it should be. This can create its own feedback loop: more monitoring leads to more overhead, which leads to lower individual output, which leads to more monitoring.
There is a concept in distributed computing called control plane overhead — the cost of managing the system as opposed to doing useful work. Every management layer, every status report, every alignment meeting is part of the control plane. The question is always: at what point does the control plane start consuming more resources than it saves?
Figure 6 — Useful work lost to coordination overhead
Part III: Healthcare — A Microcosm of System Design
Perhaps the most vivid illustration of these dynamics appears in healthcare — a domain where system architecture directly shapes the experience of something deeply personal: being sick and seeking help.
The Distributed Model
In many European countries, healthcare is structured around a distributed model. Your first point of contact is a family doctor or community clinic. For common ailments — a cold, a minor injury, a skin rash — you are typically advised to rest, take over-the-counter medication, and wait it out. Prescriptions for everyday conditions tend to carry higher dosages than their Chinese equivalents, perhaps because the system implicitly expects patients to manage more on their own between appointments.
This distributed architecture has clear advantages. Medical resources are spread across many nodes, preventing any single point from being overwhelmed. When you do get an appointment, the experience is typically unhurried — the doctor has time for you.
The disadvantage is latency. Getting an appointment can take days or weeks. For non-urgent conditions, you wait. For urgent ones, the system has emergency pathways, but the general experience is one of planned, scheduled access rather than on-demand availability.
The Centralized Model
In China, the gravitational pull is toward large urban hospitals. These institutions offer comprehensive outpatient departments covering virtually every specialty. They are efficient, high-throughput operations — and patients use them for everything from serious diagnoses to minor colds. The reasoning is understandable: why wait for a community clinic appointment when the big hospital can see you today?
The result is a system with impressive responsiveness for individual patients but enormous aggregate pressure on medical staff. Doctors see patient after patient in rapid succession. The per-patient interaction time is compressed. Quality of the individual experience suffers even as the quantity of services delivered remains high. In extreme cases, this pressure has contributed to tensions between patients and medical professionals — a systemic problem that has received significant public attention in recent years.
The Architectural Parallel
To a systems engineer, the parallel is hard to miss. This is another instance of the recurring theme: distributed load-balancing versus centralized high-throughput provision. If we think of a healthcare system as a queueing network, one model resembles a distributed multi-server queue — low utilization per server, longer routing delays, but sustainable per-node quality. The other resembles a high-throughput centralized queue — fast access, high server utilization, but risk of overload and degraded service quality under peak demand. Each optimizes for a different objective function. Could we model the transition dynamics — what happens as patient behavior shifts gradually from one architecture to the other? Where are the tipping points?
Figure 7 — Patient routing: distributed care versus hospital concentration
Part IV: What Complex Computing System Taught Me About Societies
Here is where my two worlds converge.
Lesson 1: Separate the Stable from the Volatile
In my doctoral research on virtual resource management in cloud data centers, I confronted a problem that is provably hard: optimally allocating dynamic workloads across a shifting pool of resources. No single algorithm can handle all cases optimally.
The breakthrough — modest as it was — came from separating the problem. I identified the stable components of the workload and applied mathematical optimization to those. For the volatile, unpredictable components, I used heuristic methods that did not guarantee optimality but performed well in practice. The combination outperformed either approach used alone.
This principle resonates far beyond data centers. In policy design, in organizational management, in social systems — trying to optimize everything with a single mechanism often fails. Sometimes the wisest approach is to identify what is stable and what is volatile, and apply different strategies to each.
Lesson 2: Simple Rules Often Beat Complex Plans
During my work on CPU cache replacement strategies, I observed something counterintuitive. Sophisticated, workload-aware replacement policies — designed with great care to predict access patterns — often underperformed in real-world conditions where workloads were mixed and unpredictable. Meanwhile, simple heuristics like LRU (Least Recently Used) or FIFO (First In, First Out) delivered consistently decent results across a wide range of scenarios.
The lesson was humbling: in complex systems with high uncertainty, elegantly simple rules often outperform elaborately optimized ones. The overhead of complexity — the cost of sensing, deciding, and adapting — can exceed the benefit of the optimizations it enables.
I cannot help but see echoes of this in economic and social policy. Sometimes the most effective interventions are not intricate regulatory frameworks but simple, clear rules that allow the system’s own adaptive mechanisms to operate. This is not an argument against all regulation — it is an observation that in complex adaptive systems, the relationship between mechanism complexity and outcome quality is not always linear.
Lesson 3: The Eternal Tension Between Central and Distributed
This is perhaps the most universal pattern I have encountered.
In data center architecture, centralized management gives you global visibility and the ability to compute optimal decisions — but at the cost of scalability, robustness, and communication overhead. Distributed management gives you resilience, scalability, and local responsiveness — but makes global optimization difficult and slow.
In network protocol design, the same tension appears. Should intelligence reside in the network core (where intermediate nodes have broad visibility) or at the edges (where end devices make autonomous decisions based on local conditions)? The internet’s own history has been shaped by this debate, with the end-to-end principle arguing for keeping the network core simple and pushing intelligence to the periphery.
The parallels to economic and social systems are almost too neat. Centrally planned economies offer coordinated resource allocation but struggle with information bottlenecks and adaptability. Market economies distribute decision-making to individual actors, achieving remarkable adaptability but sometimes failing at coordination for collective goals.
But real-world systems — whether computational or social — are rarely purely one or the other. The most effective architectures tend to be hybrids, with different layers of centralization and distribution applied to different aspects of the system. Understanding where to centralize and where to distribute is one of the most important design questions in any complex system.
Figure 8 — One spectrum, two domains: centralization and distribution
Where This Leads: Questions Worth Pursuing
I have deliberately left many questions open in this post, because I believe the questions are more valuable than premature answers. Here are a few that I find particularly compelling:
On social feedback loops: Can the convenience-autonomy dynamics I described be formally modeled? If we build agent-based models where individuals make local decisions about whether to provide or consume services — with service price, personal time, and social norms as variables — what macro-level patterns emerge? Are there tipping points? Equilibria? Path dependencies that explain why different societies converge on different configurations?
On organizational architecture: Is there an optimal balance between centralized control and distributed autonomy for a given type of work? How does the nature of the task (creative vs. routine, stable vs. volatile) interact with the management structure to determine outcomes? Can we simulate organizational designs and predict where the “control plane overhead” begins to outweigh its benefits?
On system design and policy: If simple rules often outperform complex ones in computational systems, does this principle transfer to social policy? Under what conditions? And how do we identify the boundary between the stable and the volatile in social systems, so we can apply the right tools to each?
On healthcare architecture: Can we model patient flow, resource utilization, and service quality under different healthcare architectures — and identify configurations that achieve both responsiveness and sustainability?
These are not idle questions. They sit at the intersection of computational science, social science, and systems engineering — a space where agent-based modeling, microsimulation, and other computational social science methods can make genuine contributions.
A Bridge Between Worlds
I started this post standing in front of a closed supermarket. I will end it by stating plainly what that moment crystallized for me.
The complex systems I have spent my career studying — data centers, processor architectures, network protocols — are human-made artifacts. They are designed, tuned, and optimized by people who understand that every architectural choice involves trade-offs, that feedback loops can amplify small differences into large divergences, and that the interaction between components matters as much as the components themselves.
Human societies are complex systems too — arguably the most complex systems there are. They are not designed from a blueprint, but they are shaped by policies, norms, institutions, and the accumulated micro-decisions of millions of individuals. The same principles that govern the behavior of distributed computing systems — feedback, emergence, trade-offs between local and global optimization, the cost of coordination — also govern the behavior of communities, organizations, and nations.
I do not pretend to have answers. But I believe that bridging the worlds of computational modeling and social science — using tools like agent-based modeling to build “artificial societies” where hypotheses can be tested, parameters can be varied, and emergent behaviors can be observed — is one of the most exciting and important research frontiers of our time.
Different social mechanisms exist for reasons. They produce different outcomes, carry different trade-offs, and serve different needs. Understanding them deeply — not to judge, but to learn — is a pursuit I find endlessly compelling. And if that understanding can eventually inform better policies, better organizations, and better lives, then it is a pursuit worth dedicating a career to.
Society, after all, is the most complex system of them all.
About the author: I hold a PhD in Computer Applied Technology, with research experience in data center resource management, embedded AI systems, and heterogeneous processor architecture simulation. My growing interest in computational social science — particularly agent-based modeling of social and collective behavior — drives me to explore how the principles of complex system design can illuminate the dynamics of human societies.